Project Blog
Early development news for my Na'vi translation project (Feb. 27, 2024)
Where to begin? I have been working on a massive Na’vi language-related programming project these last few months. Although there is still much progress to be made, I am at a point now where I feel comfortable placing my work on GitHub - after learning about Git to start!
Find the project here on Github.
Essentially, I would like to complete a program one day that utilizes the fan-maintained Na’vi dictionary over at Reykunyu.lu and is able to identify the grammatical components of Na’vi words and sentences. Using that knowledge, it can recommend translations for a translator to implement. Although I don’t know to what extent I’ll match the functionality of popular CAT/CAHT software, my goal is that the creation of large corpuses of text in Na’vi will be made possible through my program.
I consider this goal highly important for a few reasons. I believe books are a great language learning tool. They also give life to the language in a new way. Currently, Na’vi is constrained to conversations and smaller bodies of text. Books add their own whole spin to the culture of a language. It’s possible that the desire for new words (as new gaps arise in the translation process) will help the lexicon to expand. Not to mention what kind of depth might be demanded from attempting to translate a non-fiction text.
Or, imagine you would simply like a book to read to help you come across new words and sentences in an organic manner, without having to delve through old conversations or worksheets. Those have their place no doubt, however, there is something to be said about engaging with a language through the power of story. I am, of course, personally invested in the growth of the Na’vi language and its community as an Avatar fan and a linguistics fan. So maybe, we can simply say I just think it would be cool!
Now onto the meat of where my project stands. My code utilizes the Reykunyu API to retrieve data on any requested Na’vi words. Normally, this data is returned in a long line of nested text. We must extract this data and place it into a more usable and a more readable structure. Python dictionaries serve this purpose well.
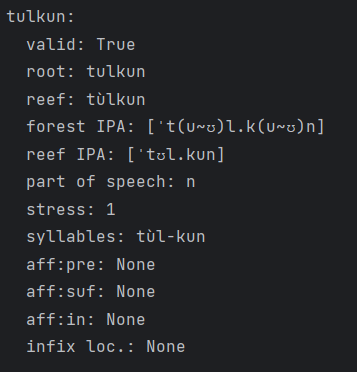
Here is an example of the data my program can return on the word tulkun!
On the word level, we are concerned primarily with orthography (spelling) and morphology (what bits and pieces are making up the word). As for orthography, in Na’vi, there are two dialects: Forest and Reef. Forest is the standard for the language as it was the only dialect of Na’vi that existed prior to the second film. However, in Reef, there are pronunciation and spelling differences, which means we must code for the ability to transition between one dialect’s spelling standards and the other’s. The orthography.py file contains the code to do this. At the moment, only the spelling of the root word can be converted, but future versions will account for affixes.
Which brings us to the next level - morphology. Depending on the part of speech, Na’vi words may have prefixes, suffixes, or infixes. Nouns, for example, can have a whole assortment of prefixes and suffixes. Verbs can take infixes in three positions (pre-first, first and second). A word cannot be accurately understood without knowing the meaning between these morphemes in a word. The same is true for English, although English morphemes follow their own grammatical rules. Currently, our code is able to retrieve data on most affixes present in Na’vi. The Reykunyu API accounts for most, but not all of these affixes. Future versions will account for shortcomings within the Reykunyu API to detect affixes.
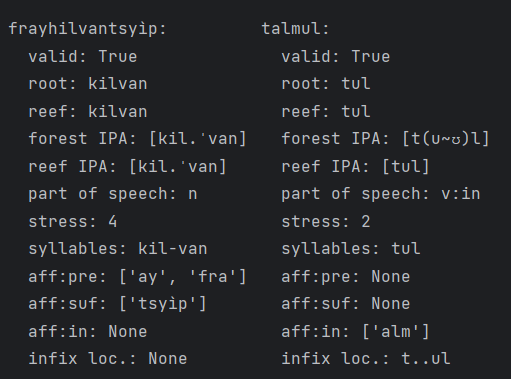
Here, frayhilvantsyìp is an example of a noun with two prefixes and one suffix. And talmul is the example of a verb with two infixes.
In total, each word gathers the following information from the API: 1) if the word is detected as a valid Na’vi word, 2) the root word in Forest Na’vi, 3) the word in Reef spelling, 4) the pronunciation of the word using IPA for both dialects, 5) its part of speech, 6) which syllable is stressed, 7) the syllables as pronounced, 8) any affixes detected, and 9) the locations where infixes go if the word is a verb.
Some of these data are simply retrieved from Reykunyu. However, others must be calculated in Python. Reef spelling undergoes an entire section of code where words are broken down into syllabic units and each syllabic unit must be checked and altered if conditions are met. For instance, the vowel “ä” becomes “e” in unstressed syllables in Reef, which means the syllabic unit which is stressed must be tracked. Stress can shift as affixes are applied, creating a bigger challenge.
That is all I can comment on for now. But feel free to reach out to me with any questions about the project or suggestions if you have any. I hope I can give another update soon, but I do not plan to do so until I move beyond morphology. In the meantime, check out my bug blog or personal blog. Hayalovay!